
Snowflake is a leading cloud data platform and SQL database. Many companies store their data in a Snowflake database.
Dask is a leading framework for scalable data science and machine learning in Python.
This article discusses why and how to use both together, and dives into the challenges of bulk parallel reads and writes into data warehouses, which is necessary for smooth interoperability. It presents the new dask-snowflake connector as the best possible solution for fast, reliable data transfer between Snowflake and Python.
Here is a video walkthrough of what that looks like:
Data warehouses are great at SQL queries but less great at more advanced operations, like machine learning or the free-form analyses provided by general-purpose languages like Python.
That's ok. If you're working as a Python data scientist or data engineer, you're probably no stranger to extracting copies of data out of databases and using Python for complex data transformation and/or analytics.
It's common to use a database and/or data warehouse to filter and join different datasets, and then pass that result off to Python for more custom computations. We use each tool where it excels. This works well as long as it is easy to perform the handoff of large results.
However, as we work on larger datasets and our results grow beyond the scale of a single machine, passing results between a database and a general purpose computation system is challenging.
This article describes a few ways in which we can move data between Snowflake and Dask today to help explain why this is both hard and important to do well, namely:
1. Use pandas and the Snowflake connector
2. Break your query up into subqueries
3. Perform a bulk export to Apache Parquet
At the end, we’ll preview the new functionality, which provides the best possible solution, and show an example of use.
There are different ways to accomplish this task, each with different benefits and drawbacks. By looking at all three, we’ll gain a better understanding of the problem, and what can go wrong.
First, if your data is small enough to fit in memory then you should just use pandas and Python. There is no reason to use a distributed computing framework like Dask if you don’t need it.
Snowflake publishes a Snowflake Python connector with pandas compatibility. The following should work fine:
//$ pip install snowflake-connector-python
>>> import snowflake
>>> df = snowflake.fetch_pandas_all(...)
//]]>

For larger datasets, we can also break one large table-scan query into many smaller queries and then run those in parallel to fill the partitions of a Dask dataframe.
This is the approach implemented in the dask.dataframe.read_sql_table function. This function does the following steps:
For example, if we’re reading from a time series then we might submit several queries which each pull off a single month of data. These each lazily return a pandas dataframe. We construct a Dask dataframe from these lazily generated subqueries.
This scales and works with any database that supports a SQLAlchemy Python connector (which Snowflake does). However, there are a few problems:
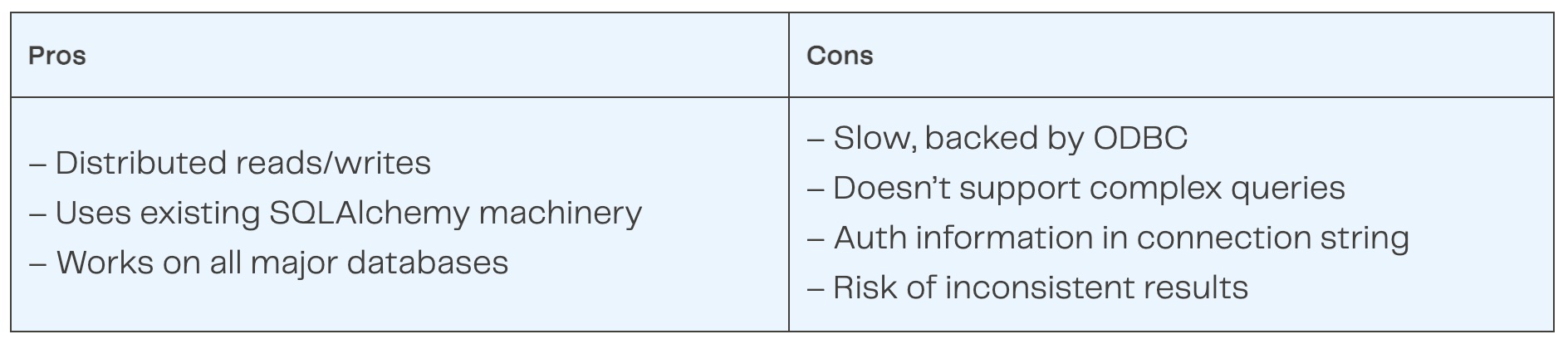
For more information see this guide to Getting Started with Dask and SQL.
We can also perform a bulk export. Both Snowflake and Dask (and really any distributed system these days) can read and write Parquet data on cloud object stores. So we can perform a query with Snowflake and then write the output to Parquet, and then read in that data with Dask dataframe.

This is great because now we can perform large complex queries and export those results at high speed to Dask in a fully consistent way. All of the challenges of the previous approach are removed.
However, this creates new challenges with data management. We now have two copies of our data. One in Snowflake and one in S3. This is technically suboptimal in many ways (cost, storage, ...) but the major flaw here is that of data organization. Inevitably these copies persist over time and get passed around the organization. This results in many copies of old data in various states of disrepair. We’ve lost all the benefits of centralized data warehousing, including cost efficiency, correct results, data security, governance, and more.
Bulk exports provide performance at the cost of the organization.
Although note, users interested in this option could also look into Snowflake Stages.
Recently, Snowflake has added a capability for staged bulk transfers to external computation systems like Dask. It combines the raw performance and support for complex queries of bulk exports, with the central management of directly reading SQL queries from the database.
Using this, we’re able to provide an excellent Snowflake <-> Dask data movement tool.
Now Snowflake can take the result of any query, and stage that result for external access.
After running the query, Snowflake gives us back a list of pointers to chunks of data that we can read. We can then send pointers to our workers and they can directly pull out those chunks of data. This is very similar to the bulk export option described above, except that now rather than us being responsible for that new Parquet-on-S3 dataset, Snowflake manages it. This gives us all of the efficiency of a bulk export, while still letting Snowflake maintain control of the resulting artifact. Snowflake can clean up that artifact for us automatically so that we’re always going back to the database as the single source of truth as we should.
Given this new capability, we then wrapped Dask around it, resulting in the following experience:
This is a smooth and simple approach that combines the best of all previous methods. It is easy to use, performs well, and maturely handles any query.
For more details on how to use distributed XGBoost training with Dask, see this GitHub repo.
There are a few things to keep in mind:
Download the dask-snowflake Jupyter Notebook to get started. If you run into any issues or have thoughts about further improvements to the package, come find us on the Dask Discourse.
The technical work described in this post was done by various engineers at Snowflake, and James Bourbeau and Florian Jetter from Coiled. Watch James Bourbeau’s talk at PyData Global 2021 together with Mark Keller and Miles Adkinds from Snowflake for a detailed walkthrough.




